This section provides an overview of the Delft AI Cluster (DAIC) infrastructure and its comparison with other compute facilities at TU Delft.
DAIC partitions and access/usage best practices
This is the multi-page printable view of this section. Click here to print.
This section provides an overview of the Delft AI Cluster (DAIC) infrastructure and its comparison with other compute facilities at TU Delft.
DAIC partitions and access/usage best practices
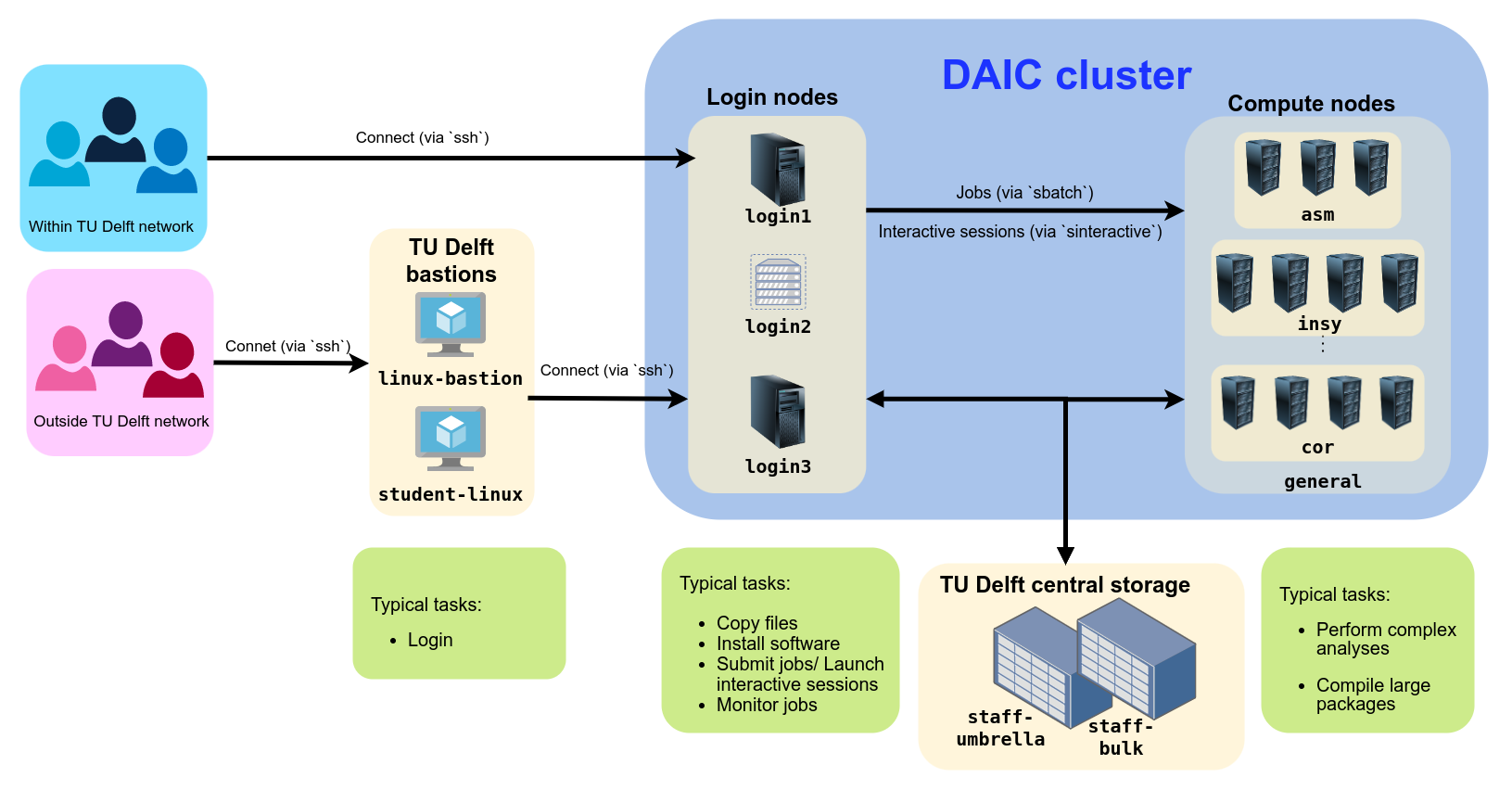
Login nodes act as the gateway to the DAIC cluster. They are intended for lightweight tasks such as job submission, file transfers, and compiling code (on specific nodes). They are not designed for running resource-intensive jobs, which should be submitted to the compute nodes.
| Hostname | CPU (Sockets x Model) | Total Cores | Total RAM | Operating System | GPU Type | GPU Count | Usage Notes |
|---|---|---|---|---|---|---|---|
login1.daic.tudelft.nl | 1 x Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz | 8 | 15.39 GB | OpenShift Enterprise | Quadro K2200 | 1 | For file transfers, job submission, and lightweight tasks. |
login2.daic.tudelft.nl | 1 x Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00GHz | 1 | 3.70 GB | OpenShift Enterprise | N/A | N/A | Virtual server, for non-intensive tasks. No compilation. |
login3.daic.tudelft.nl | 2 x Intel(R) Xeon(R) CPU E5-2683 v4 @ 2.10GHz | 32 | 503.60 GB | RHEV | Quadro K2200 | 1 | For large compilation and interactive sessions. |
login1 have been reduced to: 1 CPU, 1 GB RAM. This helps prevent system-wide instability.DAIC compute nodes are high-performance servers with multiple CPUs, large memory, and, on many nodes, one or more GPUs. The cluster is heterogeneous: nodes vary in processor types, memory sizes, GPU configurations, and performance characteristics.
If your application requires specific hardware features, you must request them explicitly in your job script (see Submitting jobs).
All compute nodes have multiple CPUs (sockets), each with multiple cores. Most nodes support hyper-threading, which allows two threads per physical core. The number of cores per node is listed in the List of all nodes section.
Request CPUs based on how many threads your program can use. Oversubscribing doesn’t improve performance and may waste resources. Undersubscribing may slow your job due to thread contention.
To request CPUs for your jobs, see Job scripts.
Many nodes in DAIC include one or more NVIDIA GPUs.GPU types differ in architecture, memory size, and compute capability. The table that follows summarizes the main GPU types in DAIC. For a per-node overview, see the List of all nodes section.
To request GPUs in your job, use
--gres=gpu:<type>:<count>. See GPU jobs for more information.
| GPU (slurm) type | Count | Model | Architecture | Compute Capability | CUDA cores | Memory |
|---|---|---|---|---|---|---|
| l40 | 18 | NVIDIA L40 | Ada Lovelace | 8.9 | 18176 | 49152 MiB |
| a40 | 84 | NVIDIA A40 | Ampere | 8.6 | 10752 | 46068 MiB |
| turing | 24 | NVIDIA GeForce RTX 2080 Ti | Turing | 7.5 | 4352 | 11264 MiB |
| v100 | 11 | Tesla V100-SXM2-32GB | Volta | 7.0 | 5120 | 32768 MiB |
In table 1: the headers denote:
Each node has a fixed amount of RAM, shown in the List of all nodes section. Jobs may only use the memory explicitly requested using --mem or --mem-per-cpu. Exceeding the allocation may result in job failure.
Memory cannot be shared across nodes, and unused memory cannot be reallocated.
For memory-efficient jobs, consider tuning your requested memorey to match your code’s peak usage closely. Fore more information, see Slurm basics.
ht), i.e, each physical core provides two logical CPUs. These are always allocated in pairs by the job scheduler (see Workload Scheduler).The following table gives an overview of current nodes and their characteristics. Use the search bar to filter by hostname, GPU type, or any other column, and select columns to be visible.
Slurm partitions typically correspond to research groups or departments that have contributed compute resources to the cluster. Most partition names follow the format <faculty>-<department> or <faculty>-<department>-<section>. A few exceptions exist for project-specific nodes.
For more information, see the Partitions section.
| Hostname | CPU (Sockets x Model) | Cores per Socket | Total Cores | CPU Speed (MHz) | Total RAM (GiB) | Local Disk (/tmp, GiB) | GPU Type | GPU Count | SlurmPartitions | SlurmActiveFeatures |
|---|---|---|---|---|---|---|---|---|---|---|
| 100plus | 2 x Intel(R) Xeon(R) CPU E5-2683 v4 @ 2.10GHz | 16 | 32 | 2097.594 | 755 | 3174 | N/A | 0 | general;ewi-insy | avx;avx2;ht;10gbe;bigmem |
| 3dgi1 | 1 x AMD EPYC 7502P 32-Core Processor | 32 | 32 | 2500.000 | 251 | 148 | N/A | 0 | general;bk-ur-uds | avx;avx2;ht;10gbe;ssd |
| 3dgi2 | 1 x AMD EPYC 7502P 32-Core Processor | 32 | 32 | 2500.000 | 251 | 148 | N/A | 0 | general;bk-ur-uds | avx;avx2;ht;10gbe;ssd |
| awi01 | 2 x Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz | 18 | 36 | 3494.921 | 376 | 393 | Tesla V100-PCIE-32GB | 1 | general;tnw-imphys | avx;avx2;ht;10gbe;avx512;gpumem32;nvme;ssd |
| awi02 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 504 | 393 | Tesla V100-SXM2-16GB | 2 | general;tnw-imphys | avx;avx2;ht;10gbe;bigmem;ssd |
| awi04 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 503 | 5529 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;imphysexclusive |
| awi08 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 503 | 5529 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;imphysexclusive |
| awi09 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 503 | 5529 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;imphysexclusive |
| awi10 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 503 | 5529 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;imphysexclusive |
| awi11 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 503 | 5529 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;imphysexclusive |
| awi12 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 503 | 5529 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;imphysexclusive |
| awi19 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 251 | 856 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;ssd |
| awi20 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 251 | 856 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;ssd |
| awi21 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 251 | 856 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;ssd |
| awi22 | 2 x Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz | 14 | 28 | 2899.951 | 251 | 856 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;ssd |
| awi23 | 2 x Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz | 18 | 36 | 2672.149 | 376 | 856 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;ssd |
| awi24 | 2 x Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz | 18 | 36 | 3299.932 | 376 | 856 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;ssd |
| awi25 | 2 x Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz | 18 | 36 | 3542.370 | 376 | 856 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;ssd |
| awi26 | 2 x Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz | 18 | 36 | 2840.325 | 376 | 856 | N/A | 0 | general;tnw-imphys | avx;avx2;ht;ib;ssd |
| cor1 | 2 x Intel(R) Xeon(R) Gold 6242 CPU @ 2.80GHz | 16 | 32 | 3573.315 | 1510 | 7168 | Tesla V100-SXM2-32GB | 8 | general;me-cor | avx;avx2;ht;10gbe;avx512;gpumem32;ssd |
| gpu01 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu02 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu03 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu04 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu05 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;ewi-st | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu06 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;ewi-st | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu07 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;ewi-st | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu08 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;ewi-st | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu09 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;tnw-imphys | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu10 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;tnw-imphys | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu11 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | bk-ur-uds;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu12 | 2 x AMD EPYC 7413 24-Core Processor | 24 | 48 | 2650.000 | 503 | 415 | NVIDIA A40 | 3 | general;ewi-st | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu14 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 503 | 856 | NVIDIA A40 | 3 | general;ewi-st | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu15 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 503 | 856 | NVIDIA A40 | 3 | general;ewi-st | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu16 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 503 | 856 | NVIDIA A40 | 3 | general;ewi-st | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu17 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 503 | 856 | NVIDIA A40 | 3 | general;ewi-st | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu18 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 503 | 856 | NVIDIA A40 | 3 | general;ewi-st | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu19 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 503 | 856 | NVIDIA A40 | 3 | general;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu20 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 1007 | 856 | NVIDIA A40 | 3 | general;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu21 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 1007 | 856 | NVIDIA A40 | 3 | general;ewi-insy-prb;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu22 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 1007 | 856 | NVIDIA A40 | 3 | general;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu23 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 1007 | 856 | NVIDIA A40 | 3 | general;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu24 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 1007 | 856 | NVIDIA A40 | 3 | general;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu25 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 1007 | 856 | NVIDIA A40 | 3 | mmll;general;ewi-insy | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu26 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 1007 | 856 | NVIDIA A40 | 3 | lr-asm;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu27 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 503 | 856 | NVIDIA A40 | 3 | me-cor;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu28 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 503 | 856 | NVIDIA A40 | 3 | me-cor;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu29 | 2 x AMD EPYC 7543 32-Core Processor | 32 | 64 | 2800.000 | 503 | 856 | NVIDIA A40 | 3 | me-cor;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu30 | 1 x AMD EPYC 9534 64-Core Processor | 64 | 64 | 2450.000 | 755 | 856 | NVIDIA L40 | 3 | ewi-insy;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu31 | 1 x AMD EPYC 9534 64-Core Processor | 64 | 64 | 2450.000 | 755 | 856 | NVIDIA L40 | 3 | ewi-insy;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu32 | 1 x AMD EPYC 9534 64-Core Processor | 64 | 64 | 2450.000 | 755 | 856 | NVIDIA L40 | 3 | ewi-me-sps;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu33 | 1 x AMD EPYC 9534 64-Core Processor | 64 | 64 | 2450.000 | 755 | 856 | NVIDIA L40 | 3 | lr-co;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu34 | 1 x AMD EPYC 9534 64-Core Processor | 64 | 64 | 2450.000 | 755 | 856 | NVIDIA L40 | 3 | ewi-insy;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| gpu35 | 1 x AMD EPYC 9534 64-Core Processor | 64 | 64 | 2450.000 | 755 | 856 | NVIDIA L40 | 3 | bk-ar;general | avx;avx2;10gbe;bigmem;gpumem32;ssd |
| grs1 | 2 x Intel(R) Xeon(R) CPU E5-2667 v4 @ 3.20GHz | 8 | 16 | 3499.804 | 251 | 181 | N/A | 0 | citg-grs;general | avx;avx2;ht;ib;ssd |
| grs2 | 2 x Intel(R) Xeon(R) CPU E5-2667 v4 @ 3.20GHz | 8 | 16 | 3499.804 | 251 | 181 | N/A | 0 | citg-grs;general | avx;avx2;ht;ib;ssd |
| grs3 | 2 x Intel(R) Xeon(R) CPU E5-2667 v4 @ 3.20GHz | 8 | 16 | 3499.804 | 251 | 181 | N/A | 0 | citg-grs;general | avx;avx2;ht;ib;ssd |
| grs4 | 2 x Intel(R) Xeon(R) CPU E5-2667 v4 @ 3.20GHz | 8 | 16 | 3500 | 251 | 181 | N/A | 0 | citg-grs;general | avx;avx2;ht;ib;ssd |
| influ1 | 2 x Intel(R) Xeon(R) Gold 6130 CPU @ 2.10GHz | 16 | 32 | 3385.711 | 376 | 197 | NVIDIA GeForce RTX 2080 Ti | 8 | influence;ewi-insy;general | avx;avx2;ht;10gbe;avx512;nvme;ssd |
| influ2 | 2 x Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz | 16 | 32 | 2300.000 | 187 | 369 | NVIDIA GeForce RTX 2080 Ti | 4 | influence;ewi-insy;general | avx;avx2;ht;10gbe;avx512;ssd |
| influ3 | 2 x Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz | 16 | 32 | 2300.000 | 187 | 369 | NVIDIA GeForce RTX 2080 Ti | 4 | influence;ewi-insy;general | avx;avx2;ht;10gbe;avx512;ssd |
| influ4 | 2 x AMD EPYC 7452 32-Core Processor | 32 | 64 | 2350.000 | 252 | 148 | N/A | 0 | influence;ewi-insy;general | avx;avx2;ht;10gbe;ssd |
| influ5 | 2 x AMD EPYC 7452 32-Core Processor | 32 | 64 | 2350 | 503 | 148 | N/A | 0 | influence;ewi-insy;general | avx;avx2;ht;10gbe;bigmem;ssd |
| influ6 | 2 x AMD EPYC 7452 32-Core Processor | 32 | 64 | 2350 | 503 | 148 | N/A | 0 | influence;ewi-insy;general | avx;avx2;ht;10gbe;bigmem;ssd |
| insy15 | 2 x Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz | 16 | 32 | 2300.000 | 754 | 416 | NVIDIA GeForce RTX 2080 Ti | 4 | ewi-insy;general | avx;avx2;ht;10gbe;avx512;bigmem;ssd |
| insy16 | 2 x Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz | 16 | 32 | 2300.000 | 754 | 416 | NVIDIA GeForce RTX 2080 Ti | 4 | ewi-insy;general | avx;avx2;ht;10gbe;avx512;bigmem;ssd |
| Total (66 nodes) | 3016 cores | 35.02 TiB | 76.79 TiB | 137 GPU |
DAIC compute nodes have direct access to the TU Delft home, group and project storage. You can use your TU Delft installed machine or an SCP or SFTP client to transfer files to and from these storage areas and others (see data transfer) , as is demonstrated throughout this page.
Unlike TU Delft’s
DelftBlue
, DAIC does not have a dedicated storage filesystem. This means no /scratch space for storing temporary files (see DelftBlue’s
Storage description
and
Disk quota and scratch space
). Instead, DAIC relies on direct connection to the TU Delft network storage filesystem (see
Overview data storage
) from all its nodes, and offers the following types of storage areas:
The Personal Storage is private and is meant to store personal files (program settings, bookmarks). A backup service protects your home files from both hardware failures and user error (you can restore previous versions of files from up to two weeks ago). The available space is limited by a quota (see Quotas) and is not intended for storing research data.
You have two (separate) home folders: one for Linux and one for Windows (because Linux and Windows store program settings differently). You can access these home folders from a machine (running Linux or Windows OS) using a command line interface or a browser via
TU Delft's webdata
. For example, Windows home has a My Documents folder. My documents can be found on a Linux machine under /winhome/<YourNetID>/My Documents
| Home directory | Access from | Storage location |
|---|---|---|
| Linux home folder | ||
| Linux | /home/nfs/<YourNetID> | |
| Windows | only accessible using an scp/sftp client (see SSH access) | |
| webdata | not available | |
| Windows home folder | ||
| Linux | /winhome/<YourNetID> | |
| Windows | H: or \\tudelft.net\staff-homes\[a-z]\<YourNetID> | |
| webdata | https://webdata.tudelft.nl/staff-homes/[a-z]/<YourNetID> | |
It’s possible to access the backups yourself. In Linux the backups are located under the (hidden, read-only) ~/.snapshot/ folder. In Windows you can right-click the H: drive and choose Restore previous versions.
To see your disk usage, run something like:
du -h '</path/to/folder>' | sort -h | tail
The Group Storage is meant to share files (documents, educational and research data) with department/group members. The whole department or group has access to this storage, so this is not for confidential or project data. There is a backup service to protect the files, with previous versions up to two weeks ago. There is a Fair-Use policy for the used space.
| Destination | Access from | Storage location |
|---|---|---|
| Group Storage | ||
| Linux | /tudelft.net/staff-groups/<faculty>/<department>/<group> or | |
/tudelft.net/staff-bulk/<faculty>/<department>/<group>/<NetID> | ||
| Windows | M: or \\tudelft.net\staff-groups\<faculty>\<department>\<group> or | |
L: or \\tudelft.net\staff-bulk\ewi\insy\<group>\<NetID> | ||
| webdata | https://webdata.tudelft.nl/staff-groups/<faculty>/<department>/<group>/ | |
The Project Storage is meant for storing (research) data (datasets, generated results, download files and programs, …) for projects. Only the project members (including external persons) can access the data, so this is suitable for confidential data (but you may want to use encryption for highly sensitive confidential data). There is a backup service and a Fair-Use policy for the used space.
Project leaders (or supervisors) can request a Project Storage location via the Self-Service Portal or the Service Desk .
| Destination | Access from | Storage location |
|---|---|---|
| Project Storage | ||
| Linux | /tudelft.net/staff-umbrella/<project> | |
| Windows | U: or \\tudelft.net\staff-umbrella\<project> | |
| webdata | https://webdata.tudelft.nl/staff-umbrella/<project> or | |
staff-umbrella, remains in a hidden .snapshot folder. If accidently deleted, you can recover such data by copying it from the (hidden).snapshot folder in your storage.Local storage is meant for temporary storage of (large amounts of) data with fast access on a single computer. You can create your own personal folder inside the local storage. Unlike the network storage above, local storage is only accessible on that computer, not on other computers or through network file servers or webdata. There is no backup service nor quota. The available space is large but fixed, so leave enough space for other users. Files under /tmp that have not been accessed for 10 days are automatically removed. A process that has a file opened can access the data until the file is closed, even when the file is deleted. When the file is deleted, the file entry will be removed but the data will not be removed until the file is closed. Therefore, files that are kept open by a process can be used for longer. Additionally, files that are being accessed (read, written) multiple times within one day won’t be deleted.
| Destination | Access from | Storage location |
|---|---|---|
| Local storage | ||
| Linux | /tmp/<NetID> | |
| Windows | not available | |
| webdata | not available | |
Using /dev/shm is very risky, and should only be done when you understand all implications. Consider using the local storage (/tmp) as a safer alternative.
Cluster-wide Risk: When memory storage fills up, it can cause memory exhaustion that kills running jobs. The scheduler cannot identify the cause, so it continues launching new jobs that will also fail, potentially making the whole cluster unusable.
Clean up policy: Users must always clean up ‘/dev/shm’ after using it, even when jobs fail or are stopped via the scheduler.
Memory storage is meant for short-term storage of limited amounts of data with very fast access on a single computer. You can create your own personal folder inside the memory storage location. Memory storage is only accessible on that computer, and there is no backup service nor quota. The available space is limited and shared with programs, so leave enough space (the computer will likely crash when you don’t!). Files that have not been accessed for 1 day are automatically removed.
| Destination | Access from | Storage location |
|---|---|---|
| Memory storage | ||
| Linux | /dev/shm/<NetID> | |
| Windows | not available | |
| webdata | not available | |
/dev/shm/ use system memory directly and do not count toward your job’s memory allocation. Request enough memory to cover both your job’s processing needs and any files stored in memory storage. Never exceed your allocated memory, not even for one second.The different storage areas accessible on DAIC have quotas (or usage limits). It’s important to regularly check your usage to avoid job failures and ensure smooth workflows.
Helpful commands
/home:$ quota -s -f ~
Disk quotas for user netid (uid 000000):
Filesystem space quota limit grace files quota limit grace
svm111.storage.tudelft.net:/staff_homes_linux/n/netid
12872M 24576M 30720M 19671 4295m 4295m
$ du -hs /tudelft.net/staff-umbrella/my-cool-project
37G /tudelft.net/staff-umbrella/my-cool-project
Or:
$ df -h /tudelft.net/staff-umbrella/my-cool-project
Filesystem Size Used Avail Use% Mounted on
svm107.storage.tudelft.net:/staff_umbrella_my-cool-project 1,0T 38G 987G 4% /tudelft.net/staff-umbrella/my-cool-project
Note that the difference is due to snapshots, which can stay for up to 2 weeks
DAIC uses the Slurm scheduler to efficiently manage workloads. All jobs for the cluster have to be submitted as batch jobs into a queue. The scheduler then manages and prioritizes the jobs in the queue, allocates resources (CPUs, memory) for the jobs, executes the jobs and enforces the resource allocations. See the job submission pages for more information.
A slurm-based cluster is composed of a set of login nodes that are used to access the cluster and submit computational jobs. A central manager orchestrates computational demands across a set of compute nodes. These nodes are organized logically into groups called partitions, that defines job limits or access rights. The central manager provides fault-tolerant hierarchical communications, to ensure optimal and fair use of available compute resources to eligible users, and make it easier to run and schedule complex jobs across compute resources (multiple nodes).
DAIC is one of several clusters accessible to TU Delft CS researchers (and their collaborators). The table below gives a comparison between these in terms of use case, eligible users, and other characteristics.
| System | Best for | Strengths | Use it when | Access & Support |
|---|---|---|---|---|
| 🎓 | AI/ML training; data-centric workflows; GPU‑intensive workloads | Large NVIDIA GPU pool (L40, A40, RTX 2080 Ti, V100 SXM2); local expert support (REIT and ICT); direct TU Delft storage | Quick iteration, hyper‑parameter sweeps, demos, and almost any workload from participating groups; queues are generally shorter than DelftBlue but limited by available GPUs | Access • Specs • Community |
| 🎓 | CPU/MPI jobs; high‑memory runs; large per-GPU memory needed; education | Large CPU pool; larger Nvidia GPUs (A100); dedicated scratch storage; local expert support (DHPC, ICT) | Many cores, tightly‑coupled MPI, long CPU jobs, or very high memory per node; education | Access • Specs • Community |
| 🎓 | Distributed systems research; streaming; edge/fog computing; in-network processing | Multi‑site testbed; mix of GPUs (16× A4000, 4× A5000) and CPUs | Cross‑cluster experiments, network‑sensitive prototypes | Access • Docs • Project |
| 🇳🇱 | National‑scale runs; larger GPU pools; cross‑institutional projects | Large CPU+GPU partitions (A100 and H100); mature SURF user support; common NL platform | When local capacity/queue limits progress or when collaborating with other Dutch institutions | Access • Docs • Specs |
| 🇪🇺 | Euro‑scale AI/data; very large GPU jobs; benchmarking at scale | Tier‑0 system with AMD MI250 GPUs (LUMI‑G); high‑performance I/O; strong EuroHPC ecosystem | Beyond Snellius capacity or part of a funded EU consortium / EuroHPC allocation | Access • Docs |
In addition to LUMI, TU Delft researchers can also apply for access to other EuroHPC Tier-0/1 systems through EuroHPC Joint Undertaking calls. Examples include:
These systems complement LUMI and broaden the options for AI, simulation, and large-scale scientific workflows at the European level.
For both education and research activities, TU Delft has established the Cloud4Research program. Cloud4Research aims to facilite the use of public cloud resources, primarily Amazon AWS. At the administrative level, Cloud4Research provides AWS accounts with an initial budget. Subsequent billing can be incurred via a project code, instead of a personal credit card. At the technical level, the ICT innovation teams provides intake meetings to facilitate getting started. Please refer to the Policies and FAQ pages for more details.